Modern AI applications need scalable, secure, and high-performance infrastructure to support machine learning in production. Traditional workflows often face challenges with deployment, GPU management, and scalability.
At OpsBee, we provide Kubernetes-native MLOps and AI Infrastructure solutions that streamline model deployment, automate ML operations, optimize GPU resources, and enable scalable AI workloads across AWS, Azure, and Google Cloud.
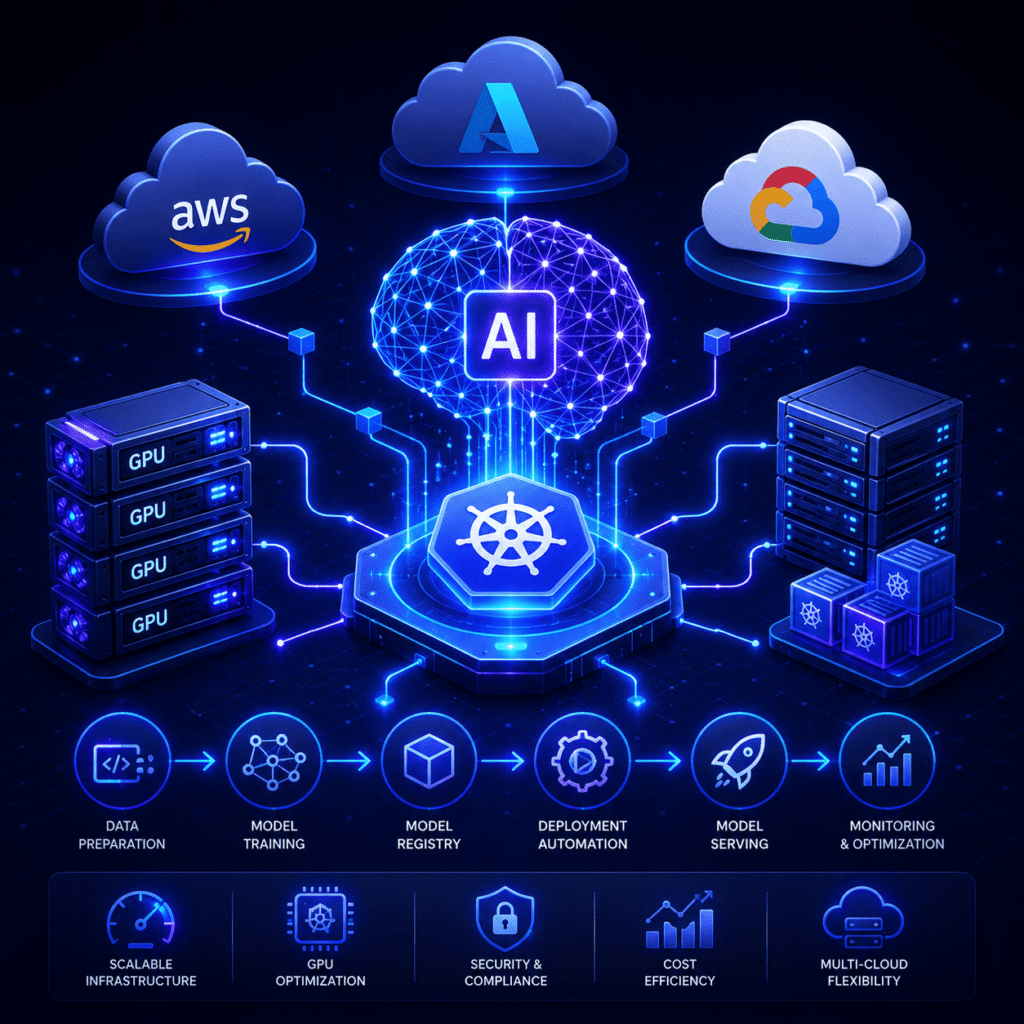
Partner with OpsBee to build intelligent, automated, and scalable AI infrastructure that supports the complete machine learning lifecycle from development to production.
Automate machine learning workflows using Kubeflow, MLflow, Apache Airflow, and cloud-native orchestration frameworks for seamless model training, validation, deployment, and monitoring.
Deploy scalable AI and machine learning models using Kubernetes-based serving platforms with automated scaling, load balancing, canary releases, and high-availability inference pipelines.
Optimize GPU workloads with intelligent autoscaling, Kubernetes GPU orchestration, NVIDIA GPU Operator integration, and cost-efficient cloud resource management.
Monitor AI model performance, detect prediction drift, track inference metrics, and automate retraining workflows using advanced observability and telemetry systems.
Deploy and manage large language models (LLMs), vector databases, Retrieval-Augmented Generation (RAG) pipelines, and generative AI applications with scalable cloud-native infrastructure.
Partner with OpsBee to build intelligent, automated, and scalable AI infrastructure that supports the complete machine learning lifecycle from development to production.
Automate machine learning workflows using Kubeflow, MLflow, Apache Airflow, and cloud-native orchestration frameworks for seamless model training, validation, deployment, and monitoring.
Deploy scalable AI and machine learning models using Kubernetes-based serving platforms with automated scaling, load balancing, canary releases, and high-availability inference pipelines.
Optimize GPU workloads with intelligent autoscaling, Kubernetes GPU orchestration, NVIDIA GPU Operator integration, and cost-efficient cloud resource management.
Monitor AI model performance, detect prediction drift, track inference metrics, and automate retraining workflows using advanced observability and telemetry systems.
Deploy and manage large language models (LLMs), vector databases, Retrieval-Augmented Generation (RAG) pipelines, and generative AI applications with scalable cloud-native infrastructure.
At OpsBee, we combine cloud engineering, Kubernetes expertise, and AI infrastructure automation to help organizations deploy, manage, and scale machine learning workloads efficiently. Our AI-first approach ensures faster model delivery, optimized GPU utilization, secure infrastructure, and reliable production operations.
Our MLOps & AI Infrastructure Services Help Organizations:
Accelerate machine learning deployment with automated MLOps pipelines that streamline model training, testing, deployment, and monitoring.
Optimize GPU utilization and reduce AI costs with Kubernetes-powered automation and scaling.
Improve model reliability through continuous monitoring, drift detection, and proactive performance optimization.
Build secure, scalable AI platforms across AWS, Azure, and GCP with cloud-native automation and reliability.
Streamline AI operations through automation, observability, and Kubernetes orchestration.
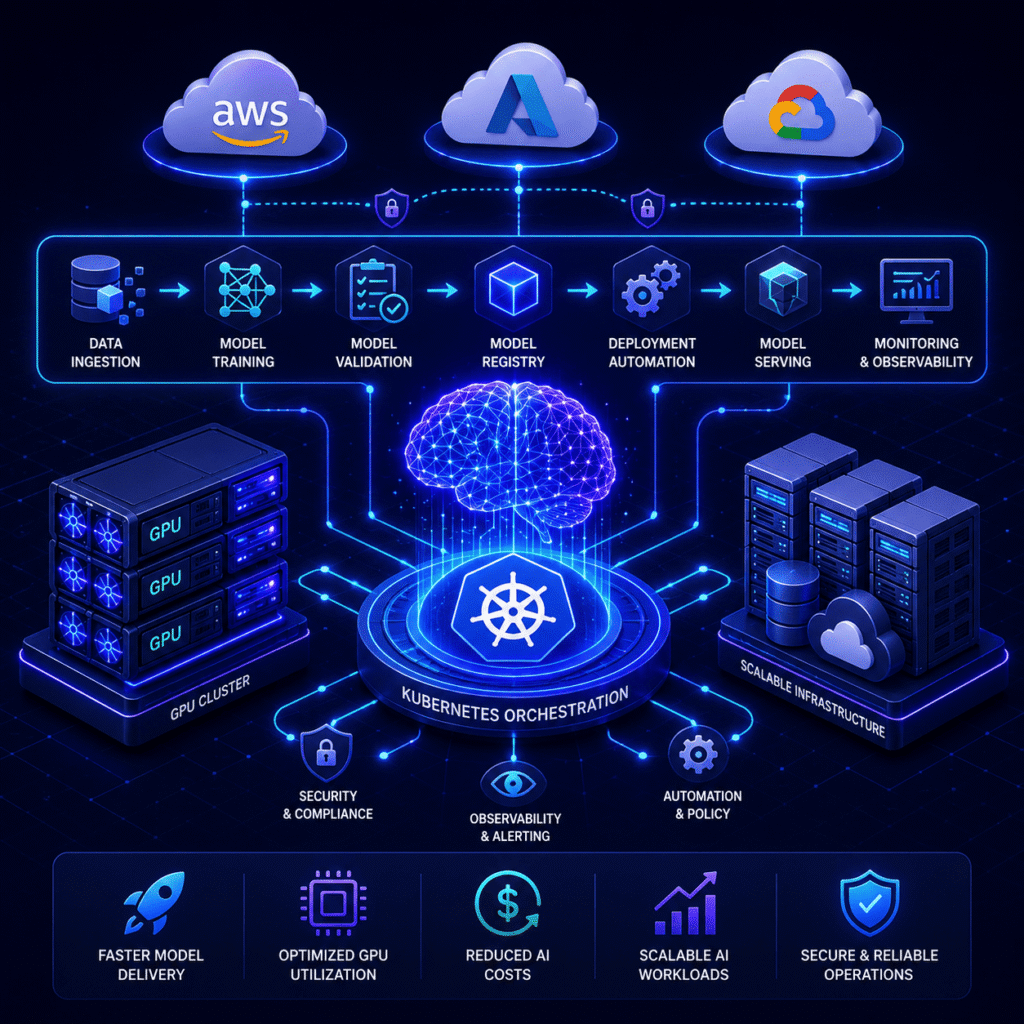
At OpsBee, we combine cloud engineering, Kubernetes expertise, and AI infrastructure automation to help organizations deploy, manage, and scale machine learning workloads efficiently. Our AI-first approach ensures faster model delivery, optimized GPU utilization, secure infrastructure, and reliable production operations.
Our MLOps & AI Infrastructure Services Help Organizations:
Accelerate machine learning deployment with automated MLOps pipelines that streamline model training, testing, deployment, and monitoring.
Optimize GPU utilization and reduce AI costs with Kubernetes-powered automation and scaling.
Improve model reliability through continuous monitoring, drift detection, and proactive performance optimization.
Build secure, scalable AI platforms across AWS, Azure, and GCP with cloud-native automation and reliability.
Streamline AI operations through automation, observability, and Kubernetes orchestration.
Successful AI operations require more than model deployment. Organizations need scalable infrastructure, continuous monitoring, automated workflows, and cost-efficient resource management to support long-term AI growth.
Automate model training, validation, deployment, and retraining workflows to accelerate AI delivery and improve operational efficiency.
Leverage Kubernetes-based GPU orchestration, autoscaling, and intelligent resource allocation to maximize performance while controlling cloud costs.
Continuously monitor model performance, detect prediction drift, and automate retraining processes to maintain accuracy and reliability.
Deploy and manage large language models (LLMs), vector databases, and RAG architectures with scalable, production-ready infrastructure.
Partner with OpsBeeTech for robust MLOps and AI infrastructure on AWS, Azure, and GCP. We help you build, deploy, and manage machine learning pipelines with automation, scalability, and reliability. Our focus is on faster model delivery, performance, and operational efficiency.
Have questions about GPU orchestration, AI model deployment, LLMOps, or scalable machine learning infrastructure? Explore some of the most common questions businesses ask before modernizing their AI operations with OpsBee.
MLOps is a set of practices that combines machine learning, DevOps, and automation to streamline model training, deployment, monitoring, and lifecycle management in production environments.
Kubernetes enables scalable AI workload orchestration, automated deployment, GPU resource management, and high-availability infrastructure for machine learning applications.
We use Kubernetes autoscaling, spot instances, GPU scheduling, and intelligent resource allocation strategies to maximize GPU utilization and reduce cloud compute expenses.
Yes. We deploy scalable LLM infrastructure, vector databases, Retrieval-Augmented Generation (RAG) pipelines, and high-performance inference systems for enterprise AI applications.
Continuous monitoring detects model drift, prediction anomalies, and performance degradation early, helping teams maintain accurate and reliable machine learning systems.
We support AWS, Microsoft Azure, Google Cloud Platform (GCP), hybrid cloud, and multi-cloud AI infrastructure environments.

OpsBee Technology stands as a leading force in the DevOps and Cloud Solutions arena, with a strategic presence in India and the USA.
Copyright © 2026 All Rights Reserved.